인공지능 모델을 만들었다면, 모델을 저장하고 활용할 수 있어야 한다.
이를 위해 Docker를 통해 이미지 빌드하고 Container를 실행하는 과정까지
포스팅 하려고 한다.
이번 글에서는 이미 저장한 모델을 가지고 Docker 중점에서 작성된 글이다.
Docker 설치
다음 사이트를 통해 Docker를 다운 받아준다.
Docker Desktop: The #1 Containerization Tool for Developers | Docker
Docker Desktop is collaborative containerization software for developers. Get started and download Docker Desktop today on Mac, Windows, or Linux.
www.docker.com



설치가 완료되었다면 컴퓨터를 다시 시작 해준다.
모델 로드 확인 ( app.py )
다음과 같은 코드를 통해 모델 로드를 확인한다.
모델을 저장할 때 환경과 동일하게 구성해야 함으로 그 때 사용했던 가상환경을 불러와 실행해 준다.
모델을 파일로 저장했다면 - 파일경로
model = tf.keras.models.load_model("model/모델 파일 경로")
모델을 h5 파일로 저장했다면 - 파일
model = tf.keras.models.load_model("model/모델 파일 명.h5")
from flask import Flask, request, jsonify
import tensorflow as tf
import numpy as np
import cv2
import os
# app = Flask(__name__)
model = tf.keras.models.load_model("./모델 경로")
print(model.summary())

flask HTTP 통신 테스트 ( app.py )
이미지 분류모델을 불러오고, 이미지를 보편적 크기인 ( 224, 224, 3 )로 resize 해준다.
이미지를 분류모델에 맞게 예측한 후 결과를 출력해 준다.
이 때 통신할 접속 경로는 (로컬호스트:5002/predict) 이다.
from flask import Flask, request, jsonify
import tensorflow as tf
import numpy as np
import cv2
from io import BytesIO
from PIL import Image
app = Flask(__name__)
model = tf.keras.models.load_model("./모델 경로")
def preprocess_image(image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
image = image.astype(np.float32) / 255.0
image = np.expand_dims(image, axis = 0)
return image
def predict(file):
image = Image.open(BytesIO(file.read()))
image = np.array(image)
processed_image = preprocess_image(image)
predictions = model.predict(processed_image)
return predictions
@app.route('/predict',methods=['POST'])
def predict_image():
if 'image' not in request.files:
return jsonify({"error" : "Not found image file"}), 400
file = request.files['image']
if file.filename == '':
return jsonify({"error" : "Not selected image file"}), 400
result = predict(file)
return jsonify({"result": int(np.argmax(result, axis=1)[0])})
if __name__ == '__main__':
app.run(debug=False, port=5002)
통신 확인
먼저 두 개의 명령 프롬프트를 실행한다.
1. conda
해당 가상환경을 실행 시키고 파일 위치로 이동 후 다음을 입력한다.
( 그렇다면 서버가 열릴 것이다. )
python app.py
2. cmd
이후 cmd에서 이미지파일과 함께 curl 명령어로 POST 요청을 한다.
이 때 상대경로가 아닌 절대경로로 C:부터 시작하여 전부 입력해준다.
- -X POST : HTTP POST 요청
- -F : multipart/form-data 형식 데이터 첨부
- image필드 파일 이름=이미지파일경
curl -X POST -F "image=@이미지 절대 경로.jpg" http://127.0.0.1:5002/predict
이후 json 형태의 파일로 결과값이 돌아온다.
{"result":모델 예측 값}
Dockerfile 생성
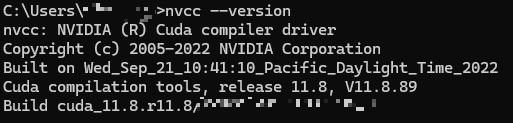
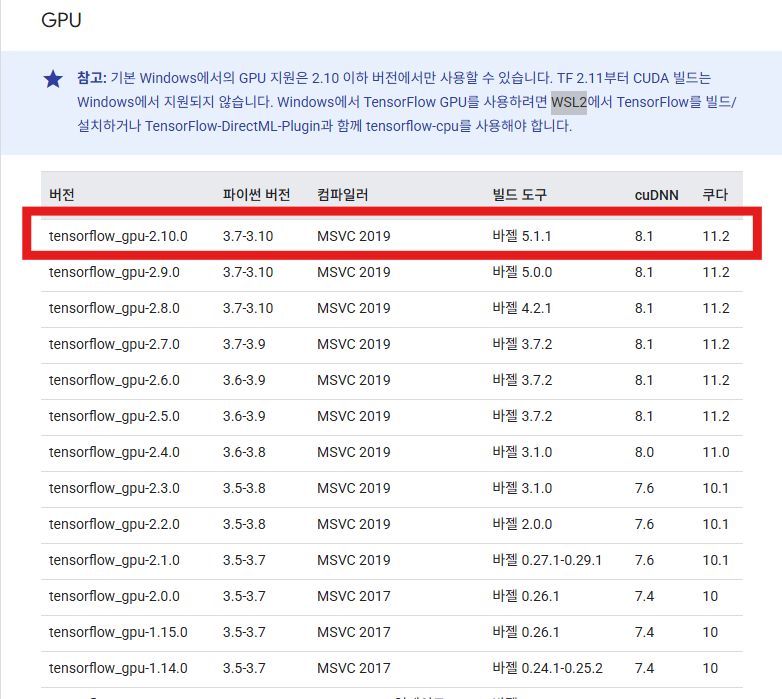
가상환경 버전 확인
실행할 때와 같이 같은 버전으로 만들어줘야 한다. 때문에 가상환경의 라이브러리들의 버전을 먼저 확인하자
다음 명령어를 통해 버전을 확인 할 수 있다.
conda list
Docker build 시 사용할 라이브러리 버전 ( requirement.txt )
다음과 같이 버전을 적어준다.
gunicorn은 flask로 배포시에 개발 서버 모드로 실행된다.
WSGI (Web Server GateWay Interface) 서버를 사용하라는 경고
flask의 내장 서버는 개발용으로만 설계되었다.
numpy=1.23.0
python=3.9.18
opencv-python=4.11.0.86
tensorflow=2.10.0
flask=3.1.0
pillow= 11.1.0 #PIL
gunicorn==20.1.0 #flask warning
Dockerfile 생성
docker build할 파일을 생성한다.
이는 txt파일로 생성한 후 확장자를 제거해준다.
# 파이썬 버전
FROM python:3.9
WORKDIR /app
# opencv에 필요한 라이브러리
RUN apt-get update && apt-get install -y \ libglib2.0-0 libsm6 libxext6 libxrender-dev libgl1-mesa-glx
# 라이브러리 버전 파일
COPY requirements.txt .
# 라이브러리 다운로드
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
# 5002 포트 개방
EXPOSE 5002
CMD ["gunicorn", "-w", "4", "-b", "0.0.0.0:5002", "app:app"]
Docker DeskTop 확인 후 실행
1. 다음 명령어를 통해 docker-desktop 가상환경이 존재하는지 확인
wsl -l -v
2. docker image build
-t : tag(이름) 설정 ex) 아래 명령어는 app이라는 이름을 가진 image 생성
. : 현재 디렉토리에서 Dockerfile를 찾아 build
docker build -t app .
3. docker container run
docker 이미지 기반으로 컨테이너를 실행
-p 5002:5002 -> 첫 번째는 호스트 머신, 두 번째는 컨테이너 내에서 사용할 포트
( localhost:5002 통해 접근하여 docker 5002 port에 전달 )
docker run -p 5002:5002 app
4. curl를 통해 post request
위와 같은 과정을 거쳤다면 cmd창에서 curl명령어를 통해 POST요청을 할 수 있다.
curl -X POST -F "image=@이미지 절대 경로.jpg" http://localhost:5002/predict
'가이드 라인 ( 설치 및 환경 설정 )' 카테고리의 다른 글
| [ Tensorflow ] Window 환경 구축 ( Window 11, RTX 3070 GPU ) 그 외 Window Guide (0) | 2025.02.15 |
|---|