이번 글에서는 백준 110번 문제를 통해 이항계수를 활용하고 최대 값을 넘어서는 순간을 다루는 방법을 알아보자.
문제 핵심
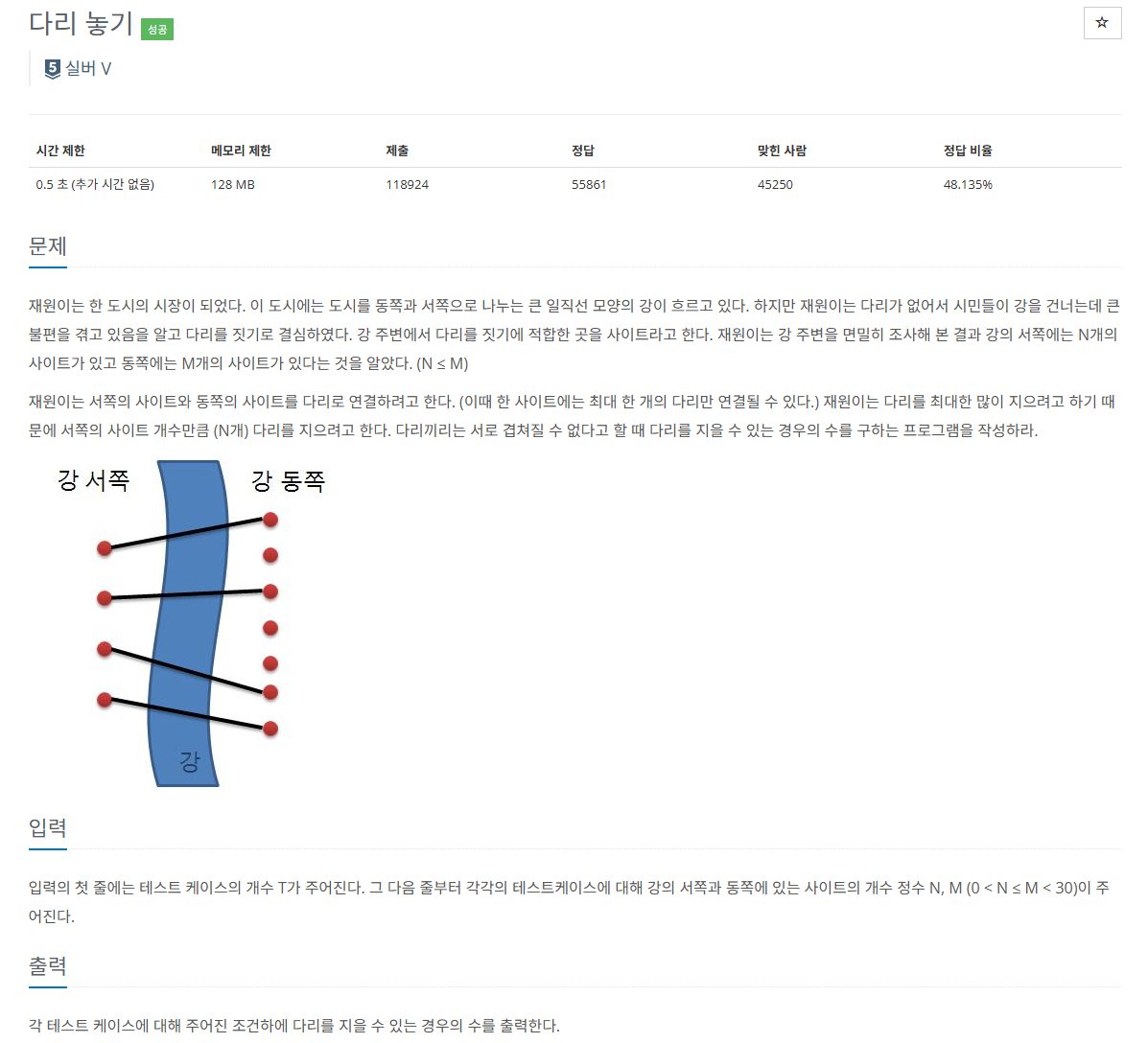
서쪽 ( N )
동쪽 ( M )
N <= M
최대 한 개의 다리만 연결
풀이 과정
이 문제는 조합론으로 mCn이라고 할 수 있다.
다만 M의 최대값이 30일 때 factorial의 값은 다음과 같다.
1! = 1
2! = 2
3! = 6
4! = 24
5! = 120
6! = 720
7! = 5040
8! = 40,320
9! = 362,880
10! = 3,628,800
11! = 39,916,800
12! = 479,001,600
13! = 6,227,020,800
14! = 87,178,291,200
15! = 1,307,674,368,000
16! = 20,922,789,888,000
17! = 355,687,428,096,000
18! = 6,402,373,705,728,000
19! = 121,645,100,408,832,000
20! = 2,432,902,008,176,640,000
21! = 51,090,942,171,709,440,000
22! = 1,124,000,727,777,607,680,000
23! = 25,852,016,738,884,976,640,000
24! = 620,448,401,733,239,439,360,000
25! = 15,511,210,043,330,985,984,000,000
26! = 403,291,461,126,605,635,584,000,000
27! = 10,888,869,450,418,352,160,768,000,000
28! = 304,888,344,611,713,860,501,504,000,000
29! = 8,841,761,993,739,701,954,543,616,000,000
30! = 265,252,859,812,191,058,636,308,480,000,000
한계는 이미 초과했다.
이 때 우리는 각 프로그래밍언어에서 제공하는 클래스를 사용하면 된다.
Java에서는 BigInteger가 있다.
핵심 코드
이항 계수1 문제 처럼 나왔지만 이번에는 동쪽이 숫자가 항상 크다.
( 값을 받을 때 반대로 받았다. 헷갈리지 않게 N M으로 선언하는게 좋다. )
int T = Integer.parseInt(bufferedReader.readLine());
int N, K;
BigInteger result;
for (int i = 0; i < T; i++) {
stringTokenizer = new StringTokenizer(bufferedReader.readLine());
K = Integer.parseInt(stringTokenizer.nextToken());
N = Integer.parseInt(stringTokenizer.nextToken());
result = factorial(N).divide(factorial(K).multiply(factorial(N - K)));
stringBuilder.append(result).append("\n");
}
이번 문제는 자료형의 최대값을 한참 넘어서기 때문에, 그 부분만 해결할 수 있다면 이전 이항계수 문제를 활용해 아주 쉽게 풀 수 있는 문제이다.
꼭 BigInteger같은 클래스를 사용하지 않더라도 비슷한 방식으로 직접 문자로 만들어서 처리하는 방법도 존재한다.
전체코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.math.BigInteger;
import java.util.StringTokenizer;
public class Main {
public static BigInteger factorial(int n) {
BigInteger result = BigInteger.ONE;
for (int i = 2; i <= n; i++) {
result = result.multiply(BigInteger.valueOf(i));
}
return result;
}
public static void main(String[] args) throws IOException {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer stringTokenizer;
StringBuilder stringBuilder = new StringBuilder();
int T = Integer.parseInt(bufferedReader.readLine());
int N, K;
BigInteger result;
for (int i = 0; i < T; i++) {
stringTokenizer = new StringTokenizer(bufferedReader.readLine());
K = Integer.parseInt(stringTokenizer.nextToken());
N = Integer.parseInt(stringTokenizer.nextToken());
result = factorial(N).divide(factorial(K).multiply(factorial(N - K)));
stringBuilder.append(result).append("\n");
}
System.out.println(stringBuilder);
}
}
내 컴퓨터를 시작으로 지인 컴퓨터 3대 조립하였다. 이번에도 지인 컴퓨터 주문이 또 들어왔다. 이번에는 그림작업 위주의 사양에 맞추긴 하지만, 금액적 한계로 본체 + 모니터 약 200 안으로 맞추기로 하였다.
부품 선정
조립시 필요한 부품은 다음과 같다. ( 본체 )
CPU
메인보드
그래픽 카드
CPU 쿨러
램 카드
ssd
파워
케이스
주로 다나와 PC견적에서 부품 선정 후 가격비교로 하나씩 구매하는 방식으로 구매하고 있다. 총 실 구매가 ( 카드 - 188만 )
선정 순서
선정 하기 전에 항상 부품 시장 조사를 하는게 아니다 보니 이런 요청이 있을 때마다 단기적으로 찾아보곤 한다.
그 때마다 즐겨보는 유튜버가 있는데 정말 초보자도 이해가 쉽게 엑셀로 정리하여 설명해주신다. 한 번 참고하길 바란다.
( 저렇게 엑셀에 하나하나 정리한 거 보고 참 대단한 사람이다 느낀다 )
1. 메인 보드 + CPU + 쿨러
메인보드와 CPU 호환성, CPU에 온도에 맞는 쿨러 선정이 우선시 된다고 생각하기에 항상 처음으로 선정한다.
CPU는 주로 I사을 선호한다.
( 물론 작업만 할 경우 높은 가격의 제품들이 필요하고 그럴 경우 멀티코어의 R사도 추천하지만,
진짜 작업만 할거라면 아예 A사 제품을 추천한다. )
그러나 겸사겸사 게임도 하고 여러 취미 생활과 중간 레벨(가격) 때문에 I사이 복합적으로 괜찮다.
메인보드는 항상 A사를 선호하는 편이다.
메인보드은 M사 와 A사를 생각하는데 같은 기판 기준 A사가 좀 더 낫다는 평이 많기도 하고, 쿨링 면에서도 우수하다.
( 실제로 A사 노트북을 사용했는데 온도 관리 측면에서 만족했다. )
다만 요즘 A/S 문제가 있다고 하는데 이 점 참고하면 되겠다.
쿨러는 공냉과 수냉 선택이 먼저인데, 내 컴퓨터는 수냉이지만, 조립 요청한 지인들 모두 공냉으로 맞춰드렸다.
이유는 둘 다 물론 관리 해야하지만, 할 줄 모른다면 공냉이 가격적으로도 괜찮다.
공냉도 영상에서 본 것으로 추천한다.
2. 그래픽 카드 ( + 램 카드 )
이후 가격에 맞춰서 그래픽 카드를 선정한다.
R사 제품도 괜찮다는 평이 몇 년전부터 있긴 했으나 N사에 대한 개인적인 생각이 확고하기 때문에 N사를 선호한다.
아직까지는 하드웨어가 비슷한 수준이라고 할 수 있으나 소프트웨어 측면에서는 아직까지는 R사는 힘들지 않나 라고 생각한다. 그만큼 지원이 많이 되는 N사 소프트웨어를 생각했을 때, 좀 더 가격을 주더라도 N제품을 사용할 것이다.
램 카드는 요즘 발전하는 속도에 비하면 최소 16G 이상이다. 여유가 있다면 32G 가 좋다.
사실 브랜드는 S사를 선호 했지만, 사실 오버 쿨럭(높은 성능) 할게 아니라면 가성비를 챙기는 게 좋은 것 같다.
때문에 영상에서 본 T사 추천한다.
3. 파워와 그 외 나머지
솔직히 파워는 S사이다. 품질상으로는 좋다고 느끼지만 가격이 비싼거는 사실이다.
같은 크기의 파워로 놓고 봤을 때 가성비를 찾는다면 M사 정도로 생각하며, 파워 전력이 올라간다면 높은 등급을 고려했으면 한다.
SSD카드도 가성비를 놓고 보면 많지만, 현재 IT 세계에서 제일 중요한 것은 데이터다.
물론 그 데이터를 인터넷에서 지키는 것도 중요하지만, 하드웨어적으로도 높은 품질을 유지해야하기 때문에 S사 추천한다.
케이스는 요즘 그래픽 카드를 생각했을 때 튼튼한게 최고다.
요즘은 그래픽 카드 지지대도 포함되서 온다.
처음 조립 당시에는 그런게 없었는데..
가격대 별로 있으나 여러개 있으나 D사 추천한다.
조립
이번에는 나름 선 정리한다고 해서 정리해 보았다.
작동 테스트
인식 확인
그래픽 드라이버 확인
매번 150 ~ 200만원의 부품들이 왔다갔다 하는데 솔직히 이제는 익숙하다고 해도 무섭다. 실수라도 하면 수십만원이 사라진다. ( 실제로 본인 본체 업그레이드 중 기존의 SSD 카드 저장 메모리 부분을 깨먹어서 날려먹었다... ) 지인 컴퓨터에서는 실수한 적 없으나 다들 조심하여 조립하기 바란다.