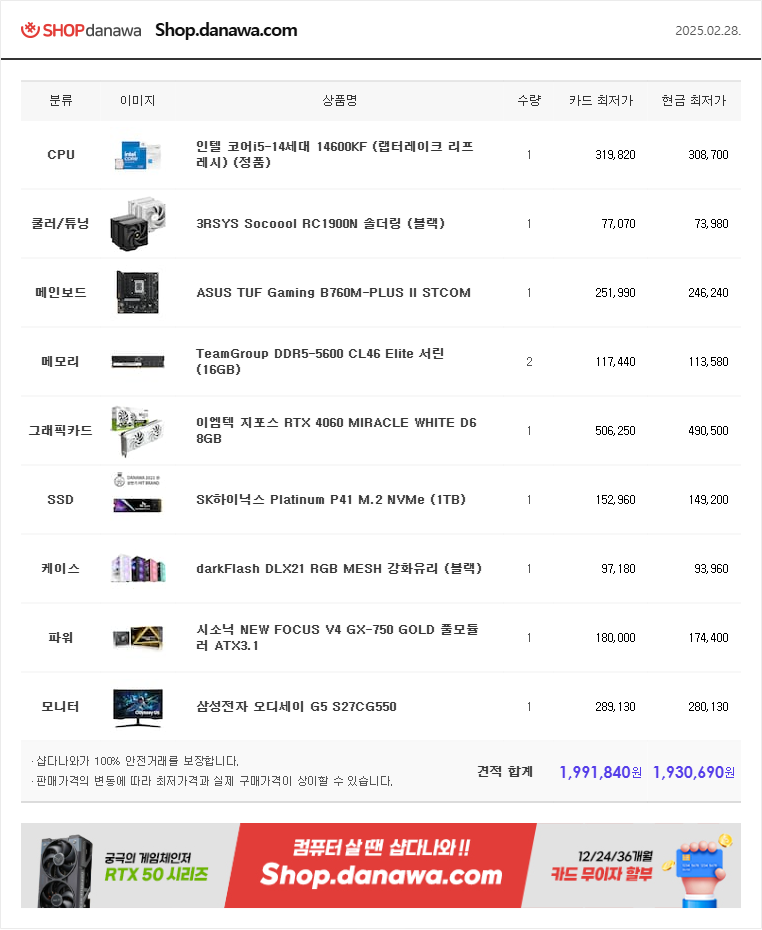
자료형 변환시 주로 ParseInt가 권장된다.
하지만 valueOf 함수도 있는데 왜 저걸 권장할까?
ParseInt()
Java 라이브러리에서 ParseInt()는 다음과 같이 정의하고 있다.
public static int parseInt(String s) throws NumberFormatException {
return parseInt(s,10);
}
기본 자료형( int )로 반환하며, 오버로딩(Overloading) 되어서 다시 재정의가 이루어진다.
다음은 오버로딩 ( Overloading ) 전체 코드이다. 문자열( s )를 진법( radix )을 통해 변환이 이루어진다.
public static int parseInt(String s, int radix)
throws NumberFormatException
{
/*
* WARNING: This method may be invoked early during VM initialization
* before IntegerCache is initialized. Care must be taken to not use
* the valueOf method.
*/
if (s == null) {
throw new NumberFormatException("Cannot parse null string");
}
if (radix < Character.MIN_RADIX) {
throw new NumberFormatException("radix " + radix +
" less than Character.MIN_RADIX");
}
if (radix > Character.MAX_RADIX) {
throw new NumberFormatException("radix " + radix +
" greater than Character.MAX_RADIX");
}
boolean negative = false;
int i = 0, len = s.length();
int limit = -Integer.MAX_VALUE;
if (len > 0) {
char firstChar = s.charAt(0);
if (firstChar < '0') { // Possible leading "+" or "-"
if (firstChar == '-') {
negative = true;
limit = Integer.MIN_VALUE;
} else if (firstChar != '+') {
throw NumberFormatException.forInputString(s, radix);
}
if (len == 1) { // Cannot have lone "+" or "-"
throw NumberFormatException.forInputString(s, radix);
}
i++;
}
int multmin = limit / radix;
int result = 0;
while (i < len) {
// Accumulating negatively avoids surprises near MAX_VALUE
int digit = Character.digit(s.charAt(i++), radix);
if (digit < 0 || result < multmin) {
throw NumberFormatException.forInputString(s, radix);
}
result *= radix;
if (result < limit + digit) {
throw NumberFormatException.forInputString(s, radix);
}
result -= digit;
}
return negative ? result : -result;
} else {
throw NumberFormatException.forInputString(s, radix);
}
}
1. 초기 예외 검사
문자열(s)가 null이면 변환이 불가 함으로 NumberFormatException 예외 발생
if (s == null) {
throw new NumberFormatException("Cannot parse null string");
}
radix(진법)이 2~36 진법 범위 내에서만 변환 가능함으로 Min, Max 값 범위 예외 처리
if (radix < Character.MIN_RADIX) {
throw new NumberFormatException("radix " + radix +
" less than Character.MIN_RADIX");
}
if (radix > Character.MAX_RADIX) {
throw new NumberFormatException("radix " + radix +
" greater than Character.MAX_RADIX");
}
2. 부호 판별 및 기본 설정
부호 +(43), -(45)은 0(48)보다 아래이기 때문에 부호를 찾고 '+'은 무시 나머지 경우에만 처리한다.
'-'인 경우 음수로 설정하고, limit를 int 자료형의 변환이기 때문에 Integer.MIN_VALUE 로 설정한다.
if (firstChar < '0') { // Possible leading "+" or "-"
if (firstChar == '-') {
negative = true;
limit = Integer.MIN_VALUE;
} else if (firstChar != '+') {
throw NumberFormatException.forInputString(s, radix);
}
길이가 1이라면 앞 부호 하나만 있기 때문에 예외 처리
if (len == 1) { // Cannot have lone "+" or "-"
throw NumberFormatException.forInputString(s, radix);
}
3. 숫자로 변환
먼저 자릿수를 가져오고, digit가 0보다 작거나 오버플로우가 나는지 체크한다.
사실 이 코드만 보고 이해하기는 어려울 수 있다. 성공과 실패의 두 가지 예시가 있다.
int multmin = limit / radix;
int result = 0;
while (i < len) {
// Accumulating negatively avoids surprises near MAX_VALUE
int digit = Character.digit(s.charAt(i++), radix);
if (digit < 0 || result < multmin) {
throw NumberFormatException.forInputString(s, radix);
}
result *= radix;
if (result < limit + digit) {
throw NumberFormatException.forInputString(s, radix);
}
result -= digit;
}
ex) 성공한 연산 10진수 "2147483647"
multmin = -2147483647 / 10 = -214748364
이 값을 통해 미리 오버플로우 발생을 예측한다.
| i |
s.charAt(i++) |
digit |
result |
result *= radix |
result -= digit |
| 1 |
' 2 ' |
2 |
0 |
0 * 10 = 0 |
0 - 2 = -2 |
| 2 |
' 1 ' |
1 |
-2 |
-2 * 10 = -20 |
-20 - 1 = -21 |
| 3 |
' 4 ' |
4 |
-21 |
-21 * 10 = -210 |
-210 - 4 = -214 |
| 4 |
' 7 ' |
7 |
-214 |
-214 * 10 = -2140 |
-2140 - 7 = -2147 |
| 5 |
' 4 ' |
4 |
-2147 |
-2147 * 10 = -21470 |
-21470 - 4 = -21474 |
| 6 |
' 8 ' |
8 |
-21474 |
-21474 * 10 = -214740 |
-214740 - 8 = -214748 |
| 7 |
' 3 ' |
3 |
-214748 |
-214748 * 10 = -2147480 |
-2147480 - 3 = -2147483 |
| 8 |
' 6 ' |
6 |
-2147483 |
-2147483 * 10 = -21474830 |
-21474830 - 6 = -21474836 |
| 9 |
' 4 ' |
4 |
-21474836 |
-21474836 * 10 = -214748360 |
-214748360 - 4 = -214748364 |
| 10 |
' 7 ' |
7 |
-214748364 |
-214748364 * 10 = -2147483640 |
-2147483640 - 7 = -2147483647 |
마지막 결과에서 -2147483647을 부호판별 후 반환한다. -(-2147483647) = 2147483647
ex) 실패한 연산 10진수 "2147483648"
| 8 |
' 6 ' |
6 |
-2147483 |
-2147483 * 10 = -21474830 |
-21474830 - 6 = -214748 36 |
| 9 |
' 4 ' |
4 |
-21474836 |
-21474836 * 10 = -214748360 |
-214748360 - 4 = -214748364 |
| 10 |
' 8 ' |
8 |
-214748364 |
-214748364 * 10 = -2147483640 |
result < limit + digit (Exception) |
다음과 같은 결과로 ( result < limt + digit ) 조건이 참이 되어 예외가 발생하게 된다.
result = -2147483640
limit = -2147483647
digit = 8
limit + digit = -2147483647 + 8 = -2147483639
valueOf()
Java 라이브러리에서 valueOf()는 다음과 같이 정의하고 있다.
public static Integer valueOf(String s) throws NumberFormatException {
return Integer.valueOf(parseInt(s, 10));
}
객체형으로 반환하고 있고, 여기서도 오버로딩( Overloading ) 했던 parseInt()가 보인다.
또 하나 valueOf 메서드도 오버로딩( Overloading ) 되었는데 다음과 같다.
1. 미리 생성된 값 IntegerCache.low(-128) ~ IntegerCache.high(127) 사이면 새 객체를 생성하지 않고 반환한다.
2. 그 값이 아니라면 새로 객체를 생성하여 반환한다.
( 미리 생성되는 값 범위는 JVM option에 따라 조정 가능 )
@IntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
(추가) parseInt() 사용 예
예제)
System.out.println(Integer.parseInt("123", 10)); // 123
System.out.println(Integer.parseInt("-123", 10)); // -123
System.out.println(Integer.parseInt("101", 2)); // 5 (2진수 변환)
System.out.println(Integer.parseInt("7F", 16)); // 127 (16진수 변환)
System.out.println(Integer.parseInt("Z", 36)); // 35 (36진수에서 'Z'는 35)
System.out.println(Integer.parseInt("007", 8)); // 7 (8진수)
예외발생)
System.out.println(Integer.parseInt("abc", 10)); // 예외 발생 (숫자가 없음)
System.out.println(Integer.parseInt("12345", 2)); // 예외 발생 (2진수 범위 초과)
System.out.println(Integer.parseInt("", 10)); // 예외 발생 (빈 문자열)
System.out.println(Integer.parseInt(null, 10)); // 예외 발생 (null)
결국 valueOf() 메서드도 parseInt()를 사용하며
Integer를 사용하지 않고, 정수만을 반환받기 원한다면 parseInt() 메서드를 사용해야 한다.
Integer객체를 통해 불필요하게 메모리를 사용하게 된다.