반응형
인공지능 모델 선정 중 무겁지 않고, 빠른 학습이 가능한 모델을 찾아보다
MobileNet을 보게 되었고, 여러 블로그와 논문을 보고 정리하는 글이다.
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce tw
arxiv.org
MobileNet ( 경량 모델 )
- 모바일 및 임베 디드 비전 애플리케이션 용
- 깊이별로 분리 가능한 컨볼류션 사용 - 가벼운 깊이를 구축
- 소규모 네트워크에 관한 많은 논문들은 크기에만 초점을 맞추고 속도는 고려하지 않는데, MobileNet은 속도를 최적화 하는데 중점을 둔다. ( 물론 소규모 네트워크도 제공 하면서 )
Depthwise Separable Convolution

- MobileNet Model은 Depthwise Separable Convolution을 기반으로 한다.
- 표준 컨볼루션 ( standard convolution)을 두 단계로 분리하는 방법입니다.
- 두 단계는 Depthwise Convolution과 1 x 1 PointWise Convolution 이다.
- Depthwise Convolution: 각 입력 채널에 단일 필터를 적용합니다. 즉, 각 채널은 독립적으로 필터링됩니다.
- 필터 적용시 Input채널의 개수와 필터의 수는 동일하게 작동합니다.
- Pointwise Convolution: 이 후, 1×1 크기의 필터를 사용하여 Depthwise Convolution의 출력들을 결합합니다.
- Depthwise Convolution: 각 입력 채널에 단일 필터를 적용합니다. 즉, 각 채널은 독립적으로 필터링됩니다.
기존 표준 컨볼루션( Standard Convolution )의 총 연산량

- Dk : 입력 값의 크기
- M : 채널 입력 수
- N : 출력 채널 수
- Df : filter 크기
Depthwise Separable Convolution
- Depthwise Convolution은 각 채널에 대해 개별적인 필터를 적용

Depthwise Separable Convolution
- Depthwise Convolution은 각 채널에 대해 개별적인 필터를 적용
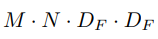
Depthwise Separable Convolution + Pointwise Convolution 연산량

Mobile Net Body Architecture
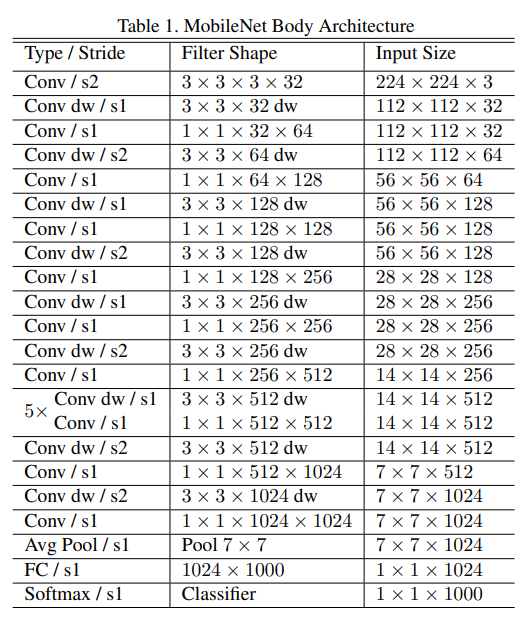
- 초반부: 3×3 Conv + Depthwise Separable Convolution로 채널 확장
- 중반부: Depthwise Conv를 반복해 특징 추출
- 후반부: 1×1 Pointwise Conv로 연산량 줄이고 Global Average Pooling 적용
- 마지막: Fully Connected Layer + Softmax로 최종 분류

- 전체 연산량 중 **1×1 컨볼루션 (Pointwise Conv)**이 94.86% 차지 → 모델 최적화의 핵심!
Width Multiplier ( α )
- 경량 네트워크이긴 하나, 특정 사용 사례에 맞춰 더 작은 모델이 필요할 수 있다.
- Width Multiplier (α) 라는 매개변수를 도입하여 네트워크의 전체적인 채널 수를 줄이는 방식을 사용.
- 특정 레이어에서 **입력 채널 수(M)과 출력 채널 수(N)**를 α 배로 줄임.
- 입력 채널: αM
- 출력 채널: αN
ex) 기본 MobileNet에서 어떤 레이어의 필터 수가 64라면,
- α = 1.0 (기본 모델) → 64개
- α = 0.75 → 48개
- α = 0.5 → 32개
- α = 0.25 → 16개
MobileNet의 연산량과 파라미터 수는 α² 비율로 감소.
- 예를 들어 α = 0.5로 설정하면, 기본 모델 대비 연산량과 파라미터 수가 약 1/4로 줄어듦.
Resolution Multiplier ( ρ )
- MobileNet에서 입력 이미지와 내부 feature map 크기를 줄이는 하이퍼파라미터입니다.
- 연산량이 ρ² 비율로 감소 (해상도가 줄어들면 픽셀 개수가 제곱 비율로 감소하기 때문)
ex ) 이미지 해상도가 224, 224 라면,
- ρ = 1.0 → 해상도 유지 (224×224)
- ρ = 0.75 → 해상도가 75%로 감소 (192×192)
- ρ = 0.5 → 해상도가 50%로 감소 (112×112)
- ρ = 0.25 → 해상도가 25%로 감소 (56×56)
트레이드 오프 ( Trade-off )
- α를 줄이면 모델 크기가 감소하여 속도가 빨라지지만, 정확도도 떨어질 수 있음.
- 적절한 α 값을 선택하여 성능과 속도의 균형을 맞추는 것이 중요.
- 연산량이 ρ² 비율로 감소하여 속도가 빨라지지만, 정확도도 떨어질 수 있음.
- 하지만 해상도가 줄어들면 모델의 정확도가 낮아질 가능성이 있음
무거운 모델에 비해 다소 정확도가 낮을 수 있지만 ,
소규모 모델은 빠른 속도와 더 적은 리소스를 요구하는 장점이 있다.
이러한 점들을 고려하여 현재 모델을 배포할 환경에 맞는 선택을 하는 것이 중요하다.
또한, 데이터 가공 역시 중요한 요소이므로 이를 병행하여 고려하는 것이 좋다.
반응형



